# Cortex
## 项目简介
Cortex是基于Proemtheus实现的集群监控方案,具有水平拓展,高可用,多租户,长期存储等特点。
项目由Tom Wilkie和Julius Volz创建于2016年2月份。在2018年8月成为CNCF沙盒项目。项目维护成员主要来自于Weavework。
## 官方网站
{% embed url="" %}
## 项目地址
{% embed url="" %}
## 架构图
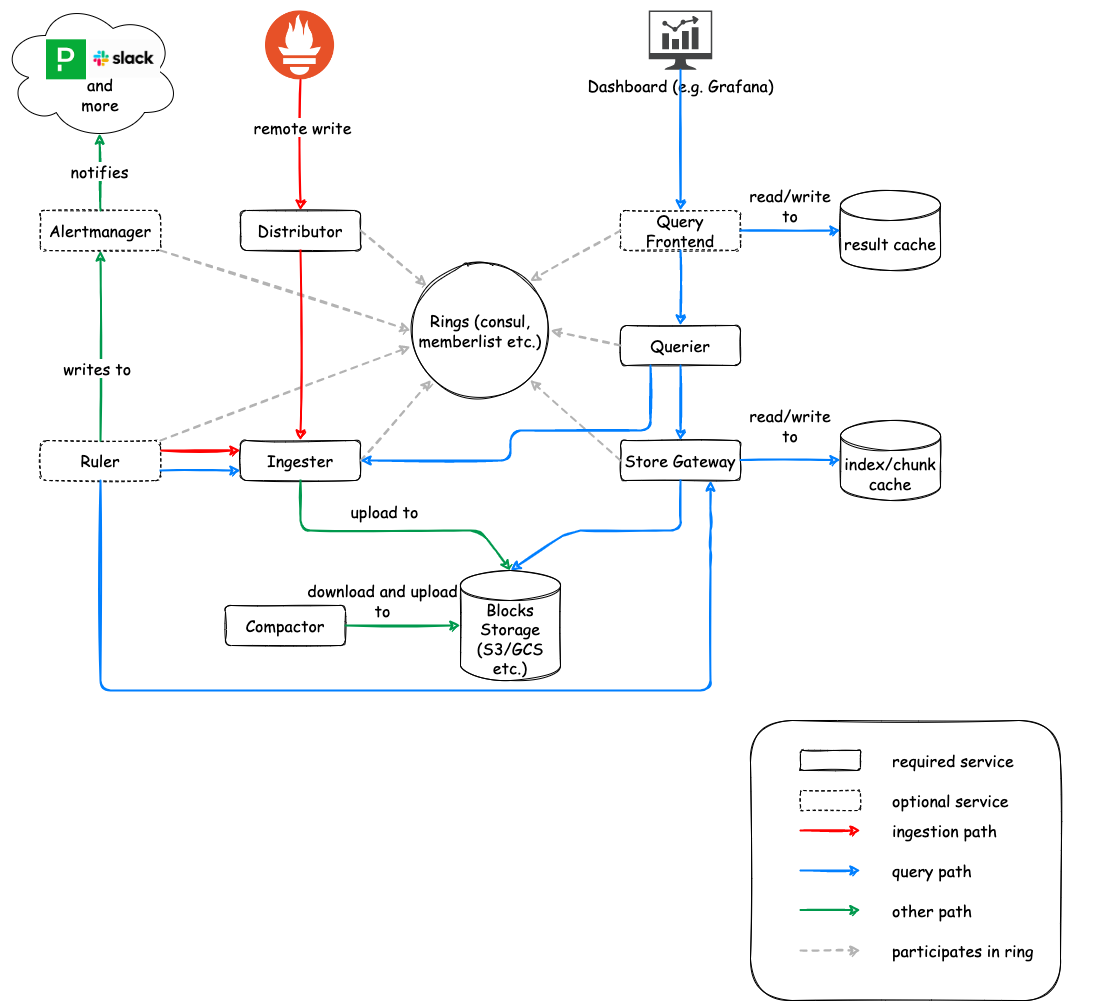
## 组件介绍
* Distributor。用于接收并分发各个租户的写入请求,接收来自prometheus的remote write API写入数据。对写入的数据进行过滤和去重,将结果存入ingester。
* Ingester。用于存储短期的指标数据,并定期将数据刷写到后端存储中。同时提供了用于查询短期指标数据的查询接口。
* Querier。实现了与prometheus相同的查询接口,处理来自外部的查询请求。对TSDB的index和chunks进行缓存以加速查询。在部署了Query Frontend的情况下则作为处理子查询的工作节点。
* Query Frontend(可选)。实现了与prometheus相同的查询接口,处理来自外部的查询请求。将单个大查询拆分为多个子查询并放入查询队列,交由querier完成查询后进行汇聚,同时也会对查询结果进行缓存用以加速查询。
* Config(可选)。作为租户的alertmanager配置,规则和模板的配置接口。
* Ruler(可选)。用以评估每个租户的recording和alerting规则。将recording结果写入ingester,将告警消息发送到alertmanager。
* Alertmanager(可选)。向租户发送告警通知,基于prometheus的alertmanager做的进一步拓展,支持多租户。
## 工作机制
### 数据写入
1. Prometheus将采集到的指标数据推送到Cortex网关,由网关将请求代理到Distributor上。
2. Distributor对写入的内容进行格式校验,包括指标的名称格式,标签格式,标签数量和时间戳范围。
3. Distributor对数据以集群标签为分组,副本标签为依据进行去重,保证来自于同一个Prometheus集群的数据只保留一个副本。
4. Distributor根据副本因子(表示写多少个副本的数据)通过哈希计算将写入请求分批次,以副本因子数分发给多个Ingester实例。
5. Ingester首先将写入请求记录到WAL中,再按顺序消费记录到chunks中,在生成一个chunks(12小时)之后,将chunks和index分别写入到后端存储中,同时进行缓存更新。
### 数据查询
1. 用户向Cortex网关发起查询请求,由网关将请求代理到QueryFrontend。
2. QueryFrontend首先从缓存中查询是否有满足查询条件的内容,根据缓存中缺少的时间段补齐生成多个子查询放入查询队列中。
3. Querier向Query Frontend消费查询队列,获取子查询。
4. Querier根据子查询从缓存中尝试读取满足条件的index和chunks,缺失的时间段如果在12小时内则向Ingester查询,确实的时间段如果在12小时外则向后端存储查询。
5. Querier将查询结果返回给Query Frontend,并缓存index和chunks。
6. Query Frontend对Query的返回结果进行汇聚和对其,返回查询结果并将结果更新到结果缓存中。
### 告警发送
1. 租户根据自身需要将alertmanager配置,recording规则,alerting规则和告警消息模板配置发送到Cortex网关,由网关代理到Config上。
2. Config将配置写入到PostgresSQL。
3. Ruler从Config读取到各个租户的配置规则,生成对应的recording规则和alerting规则进行评估。
4. Ruler将告警消息发送至Alertmanager发出告警。
5. Ruler将规则评估结果写入Ingester。
## 优势特性
* 全局查询。基于租户级别的全局查询。
* 水平拓展。各个组件都支持水平拓展,可以提升整体的写入和查询性能。
* 长期存储。Ingester做为长期数据写入的唯一入口,每当本地生成12小时长的chunks时,会将该chunks以及对应的index上传到存储后端,需要注意的是index和chunks分开存储。
* 多租户。租户间的查询,配置写入都是隔离的,互相不可见。所有的Cortex组件在发送的请求中都会携带一个Header X-Scope-OrgID,表示租户ID。当Ingester在写入数据时发现有一个新的租户ID时,则认为这是一个新的租户,当Querier在读取数据时,会请求中的租户ID是否已经存在。创建新租户的过程是随着指标数据的写入自动完成的,不存在租户的创建或删除接口,也不存在租户的鉴权和认证,这些需要在入口网关中实现。
## 缺点
1. 需要依赖多种第三方中间件,提升了运维的难度
2. 官方文档中部分组件的介绍不够完整甚至没有介绍
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://viva.gitbook.io/project/cloud-native/prometheus/cortex.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.